Understanding
the Oracle architecture is paramount to managing a database. If you
have a sound knowledge of the way Oracle works, it can help all sorts of
things:
✓ Troubleshooting
✓ Recovery
✓ Tuning
✓ Sizing
✓ Scaling
✓ Troubleshooting
✓ Recovery
✓ Tuning
✓ Sizing
✓ Scaling
An
instance is the combination of memory and processes that are part of a
running installation. The database is the physical component or the
files. You might hear people use the term database instance to refer to
the
entire running database. However, it’s important to understand the distinction between the two.
Here are some rules to consider:
✓ An instance can exist without a database. Yes, it’s true. You can start an Oracle instance and not have it access any database files. Why would you do this?
• This is how you create a database. There’s no chicken-or-egg debate here. You first must start an Oracle instance; you create the database from within the instance.
• An Oracle feature called Automatic Storage Management uses an instance but isn’t associated with a database.
✓ A database can exist without an instance, but would be useless. It’s just a bunch of magnetic blips on the hard drive.
✓ An instance can only access one database. When you start your instance, the next step is to mount that instance to a database. An instance can only mount one database at a time.
✓ You can set up multiple instances to access the same set of files or one database. Clustering is the basis for Oracle’s Real Application Clusters feature. Many instances on several servers accessing one central database allows for scalability and high availability.
entire running database. However, it’s important to understand the distinction between the two.
Here are some rules to consider:
✓ An instance can exist without a database. Yes, it’s true. You can start an Oracle instance and not have it access any database files. Why would you do this?
• This is how you create a database. There’s no chicken-or-egg debate here. You first must start an Oracle instance; you create the database from within the instance.
• An Oracle feature called Automatic Storage Management uses an instance but isn’t associated with a database.
✓ A database can exist without an instance, but would be useless. It’s just a bunch of magnetic blips on the hard drive.
✓ An instance can only access one database. When you start your instance, the next step is to mount that instance to a database. An instance can only mount one database at a time.
✓ You can set up multiple instances to access the same set of files or one database. Clustering is the basis for Oracle’s Real Application Clusters feature. Many instances on several servers accessing one central database allows for scalability and high availability.
Oracle Architecture can be divided into 3 parts:
- Memory: The memory components of Oracle (or any software, for that matter) are what inhabit the RAM on the computer. These structures only exist when the software is running. For example, they instantiate when you start an instance. Some of the structures are required for a running database; others are optional. You can also modify some to change the behavior of the database, while others are static.
- Processes: Again, Oracle processes only exist when the instance is running. The running instance has some core mandatory processes, whereas others are optional, depending on what features are enabled. These processes typically show up on the OS process listing.
- Files and structures: Files associated with the database exist all the time — as long as a database is created. If you just install Oracle, no database files exist. The files show up as soon as you create a database. As with memory and process, some files are required whereas others are optional. Files contain your actual database objects: the things you create as well as the objects required to run the database. The logical structures are such things as tables, indexes, and programs.
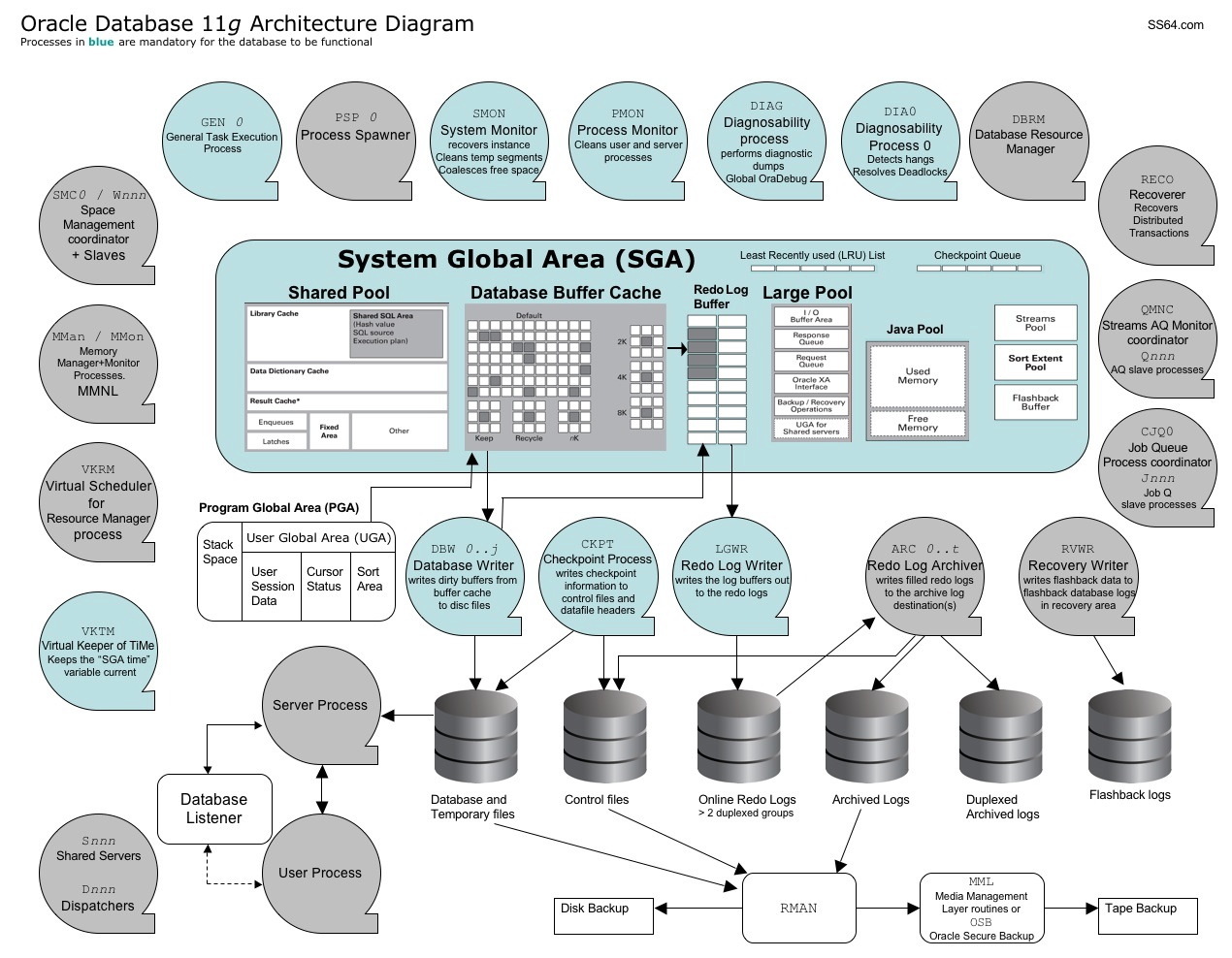
What is a SGA ????
The
System Global Area (SGA) is a group of shared memory structures. It
contains things like data and SQL. It is shared between both Oracle
background processes and server processes.
The SGA is made up of several parts called the SGA components:
✓ Shared pool
✓ Database buffer cache
✓ Redo log buffer
✓ Large pool
✓ Java pool
The SGA is made up of several parts called the SGA components:
✓ Shared pool
✓ Database buffer cache
✓ Redo log buffer
✓ Large pool
✓ Java pool
A
cache is a temporary area in memory created for a quick fetch of
information that might otherwise take longer to retrieve. For example,
the cache’s mentioned in the preceding list contain pre-computed
information. Instead of a user having to compute values every time, the
user can access the information in a cache.
The library cache
The library cache is just like what it’s called: a library. More specifically, it is a library of ready-to-go SQL statements.
Each time you execute a SQL statement, a lot happens in the background. This background activity is called parsing. Parsing can be quite expensive.
During parsing, some of these things happen:
✓ The statement syntax is checked to make sure you typed everything correctly.
✓ The objects you’re referring to are checked. For example, if you’re trying access a table called emp, Oracle makes sure it exists in the database.
✓ Oracle makes sure that you have permission to do what you’re trying to do.
✓ The code is converted into a database-ready format. The format is called byte-code or p-code.
✓ Oracle determines the optimum path or plan. This is by far the most expensive part.
Every time you execute a statement, the information is stored in the library cache. That way, the next time you execute the statement not much has to occur (such as checking permissions).
The dictionary cache
The dictionary cache is also frequently used for parsing when you execute SQL. You can think of it as a collection of information about you and the database’s objects. It can check background-type information.
The dictionary cache is also governed by the rules of the Least Recently Used (LRU) algorithm: If it’s not the right size, information can be evicted.
Not having enough room for the dictionary cache can impact disk usage. Because the definitions of objects and permission-based information are stored in database files, Oracle has to read disks to reload that information into the dictionary cache. This is more time-consuming than getting it from the memory cache. Imagine a system with thousands of users constantly executing SQL . . . an improperly sized dictionary cache can really hamper performance.
Like the library cache, you can’t control the size of the dictionary cache directly. As the overall shared pool changes in size, so does the dictionary cache.
The quickest result cache
The result cache is a new Oracle 11g feature and it has two parts:
✓SQL
result cache: This cache lets Oracle see that the requested data —
requested by a recently executed SQL statement — might be stored in
memory. This lets Oracle skip the execution part of the, er, execution,
for lack of a better term, and go directly to the result set, if it
exists. What if your data changes? We didn’t say this is the
end-all-performance woes feature. The SQL result cache works best on
relatively static data
(like the description of an item on an e-commerce site). Should you worry about the result cache returning incorrect data? Not at all. Oracle automatically invalidates data stored in the result cache if any of the underlying components are modified.
✓ PL/SQL function result cache: The PL/SQL function result cache stores the results of a computation. For example, say you have a function that calculates the value of the dollar based on the exchange rate of the Euro. You might not want to store that actual value since it changes constantly. Instead, you have a function that calls on a daily or hourly rate to determine the value of the dollar. In a financial application this could happen thousands of times an hour. Therefore, instead of the function executing, it goes directly to the PL/SQL result cache to get the data between the rate updates. If the rate does change, then Oracle re-executes the function and updates the result cache.
(like the description of an item on an e-commerce site). Should you worry about the result cache returning incorrect data? Not at all. Oracle automatically invalidates data stored in the result cache if any of the underlying components are modified.
✓ PL/SQL function result cache: The PL/SQL function result cache stores the results of a computation. For example, say you have a function that calculates the value of the dollar based on the exchange rate of the Euro. You might not want to store that actual value since it changes constantly. Instead, you have a function that calls on a daily or hourly rate to determine the value of the dollar. In a financial application this could happen thousands of times an hour. Therefore, instead of the function executing, it goes directly to the PL/SQL result cache to get the data between the rate updates. If the rate does change, then Oracle re-executes the function and updates the result cache.
Database buffer cache
The database buffer cache is typically the largest portion of the SGA. It has data that comes from the files on disk. Because accessing data from disk is slower than from memory, the database buffer cache’s sole purpose is to cache the data in memory for quicker access.
The database buffer cache can contain data from all types of objects:
✓ Tables
✓ Indexes
✓ Materialized views
✓ System data
In the phrase database buffer cache the term buffer refers to database blocks. A database block is the minimum amount of storage that Oracle reads or writes. All storage segments that contain data are made up of blocks. When you request data from disk, at minimum Oracle reads one block. Even if you request only one row, many rows in the same table are likely to be retrieved. The same goes if you request one column in one row. Oracle reads the entire block, which most likely has many rows, and all columns for that row.
It’s feasible to think that if your departments table has only ten rows, the entire thing can be read into memory even if you’re requesting the name of only one department.
Buffer cache state
The buffer cache controls what blocks get to stay depending on available space and the block state (similar to how the shared pool decides what SQL gets to stay). The buffer cache uses its own version of the LRU algorithm.
The buffer cache controls what blocks get to stay depending on available space and the block state (similar to how the shared pool decides what SQL gets to stay). The buffer cache uses its own version of the LRU algorithm.
A block in the buffer cache can be in one of three states:
✓ Free: Not currently being used for anything
✓ Pinned: Currently being accessed
✓ Dirty: Block has been modified, but not yet written to disk
✓ Free: Not currently being used for anything
✓ Pinned: Currently being accessed
✓ Dirty: Block has been modified, but not yet written to disk
Block write triggers
What triggers a block write and therefore a dirty block?
✓ The database is issued a shutdown command.
✓ A full or partial checkpoint occurs — that’s when the system periodically dumps all the dirty buffers to disk.
✓ A recovery time threshold, set by you, is met; the total number of dirty blocks causes an unacceptable recovery time.
✓ A free block is needed and none are found after a given amount of searching.
✓ Certain data definition language (DDL) commands.
What triggers a block write and therefore a dirty block?
✓ The database is issued a shutdown command.
✓ A full or partial checkpoint occurs — that’s when the system periodically dumps all the dirty buffers to disk.
✓ A recovery time threshold, set by you, is met; the total number of dirty blocks causes an unacceptable recovery time.
✓ A free block is needed and none are found after a given amount of searching.
✓ Certain data definition language (DDL) commands.
✓ Every three seconds.
✓ Other reasons. The algorithm is complex and we can’t be certain with all the changes that occur with each software release.
✓ Other reasons. The algorithm is complex and we can’t be certain with all the changes that occur with each software release.
The fact is the database stays pretty busy writing blocks in an environment where there are a lot changes.
Redo log buffer
The redo log buffer is another memory component that protects you from yourself, bad luck, and Mother Nature. This buffer records every SQL statement that changes data. The statement itself and any information required to reconstruct it is called a redo entry. Redo entries hang out here temporarily before being recorded on disk. This buffer protects against the loss of dirty blocks.
Dirty blocks aren’t written to disk constantly.
Imagine that you have a buffer cache of 1,000 blocks and 100 of them are dirty. Then imagine a power supply goes belly up in your server and the whole system comes crashing down without any dirty buffers being written.
That data is all lost, right? Not so fast. . . .
The redo log buffer is flushed when these things occur:
✓ Every time there’s a commit to data in the database
✓ Every three seconds
✓ When the redo buffer is 1⁄3 full
✓ Just before each dirty block is written to disk
Why
does Oracle bother maintaining this whole redo buffer thingy when
instead, it could just write the dirty buffers to disk for every commit?
It seems redundant.
✓ The file that records this information is sequential. Oracle always writes to the end of the file. It doesn’t have to look up where to put the data. It just records the redo entry. A block exists somewhere in a file. Oracle has to find out where, go to that spot, and record it. Redo buffer writes are very quick in terms of I/O.
✓ One small SQL statement could modify thousands or more database blocks. It’s much quicker to record that statement than wait for the I/O of thousands of blocks. The redo entry takes a split second to write, which reduces the window of opportunity for failure. It also only returns your commit if the write is successful. You know right away that your changes are safe. In the event of failure, the redo entry might have to be re-executed during recovery, but at least it isn’t lost.
✓ The file that records this information is sequential. Oracle always writes to the end of the file. It doesn’t have to look up where to put the data. It just records the redo entry. A block exists somewhere in a file. Oracle has to find out where, go to that spot, and record it. Redo buffer writes are very quick in terms of I/O.
✓ One small SQL statement could modify thousands or more database blocks. It’s much quicker to record that statement than wait for the I/O of thousands of blocks. The redo entry takes a split second to write, which reduces the window of opportunity for failure. It also only returns your commit if the write is successful. You know right away that your changes are safe. In the event of failure, the redo entry might have to be re-executed during recovery, but at least it isn’t lost.
Large pool
The large pool relieves the shared pool of sometimes-transient memory requirements.
These features use the large pool:
✓ Oracle Recovery Manager
✓ Oracle Shared Server
✓ Parallel processing
✓ I/O-related server processes
These features use the large pool:
✓ Oracle Recovery Manager
✓ Oracle Shared Server
✓ Parallel processing
✓ I/O-related server processes
Because many of these activities aren’t constant and only allocate memory when they’re running, it’s more efficient to let them execute in their own space.
Without a large pool configured, these processes steal memory from the shared pool’s SQL area. That can result in poor SQL processing and constantresizing of the SQL area of the shared pool. Note: The large pool has no LRU. Once it fills up (if you size it too small) the processes revert to their old behavior of stealing memory from the shared pool. REAL CATCH in PERFORMANCE TUNING!!!!!
Java pool
The Java pool is an optional memory component. Starting in Oracle 8i, the database ships with its own Java Virtual Machine (JVM), which can execute Java code out of SGA.
Program Global Area
The Program Global Area (PGA) contains information used for private or session-related information that individual users need.
Again, this used to be allocated out of the shared pool. In Oracle 9i, a memory structure called the instance PGA held all private information as needed. This alleviated the need for the shared pool to constantly resize its SQL area to meet the needs of individual sessions. Because the amount of users constantly varies, as do their private memory needs, the instance PGA was designed for this type of memory usage.
The PGA contains the following:
✓ Session memory
• Login information
• Information such as settings specific to a session (for example, what format to use when dates are displayed)
✓ Private SQL area
• Variables that might be assigned values during SQL execution
• Work areas for processing specific SQL needs: sorting, hash-joins, bitmap operations and Cursors.
No comments:
Post a Comment